AI Workbench
The workbench allows you to evaluate queries with a language model. One important aspect to note is that it is able to process variables within the text that is passed to the large language model (LLM).
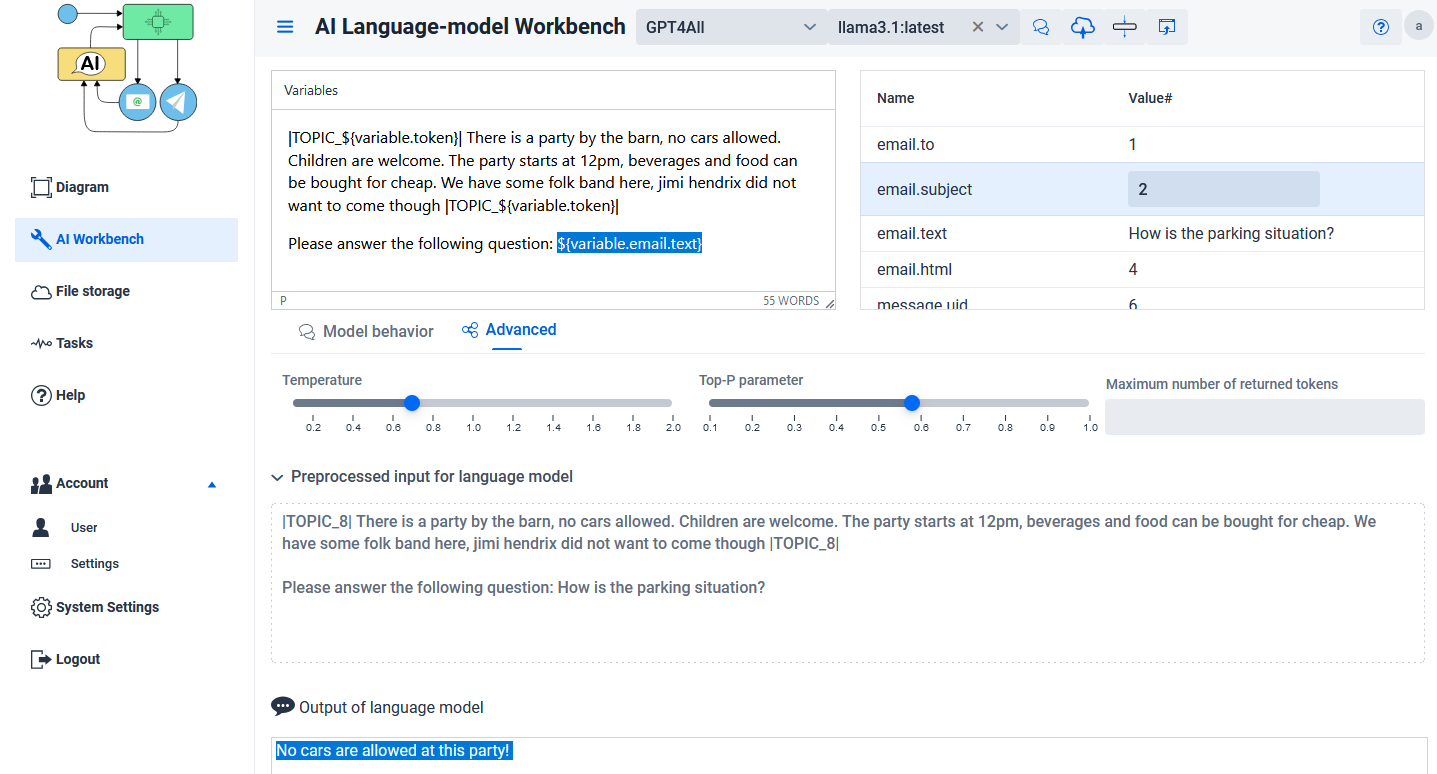
If the node is connected within the diagram it shows the set of variables that are available from earlier activities, you can edit the value to test the prompt with the language model.
Actions
-
Send request
sends a request to the language model
-
Save
Save the changes and return if opened via the wrench button from an AI text prompt request node in the diagram editor
-
Create in editor Create a new node in the diagram editor with the evaluated prompt settings
Advanced
Some advanced settings that can be used to control the behavior of the returned text in the LLM.
-
Temperature
What sampling temperature to use, between 0 and 2. Higher values like 0.8 will make the output more random, while lower values like 0.2 will make it more focused and deterministic.
-
Top-P
This is called nucleaus sampling, an alternative to sampling with temperature; 0.1 means only the tokens comprising the top 10% probability is considered.
-
Maximum number of returned tokens This the maximum length of text that the model should create. It is usually limited by the context size.
Statement for model behavior (system prompt)
This is a special part of the prompt that is always sent. It is used to give detailed descriptions of how the model should 'behave' by describing properties to affect the type of answering. System prompts have a specific format depending on the model
Preprocessed input of language model / Output of the language model
The first textfield shows the processed text that is finally sent to the language model to request an answer.
The second field shows the query result after a request has been sent.